
Capturing the Essence: An In-Depth Exploration of Automatic Image Captioning Techniques and Advancements
Article Sidebar
Main Article Content
Abstract
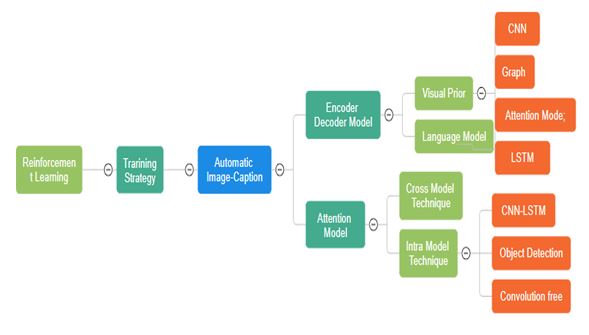
This comprehensive overview offers a deep dive into the quickly developing topic of automatic image captioning. It provides a thorough examination of the many approaches, datasets, and assessment criteria applied in the production of written descriptions from visual content. With an emphasis on the extensively used MS COCO dataset, the article explores the critical significance of datasets in addition to exploring the nuances of cutting-edge image captioning algorithms. It also goes over the fundamental function of assessment metrics, stressing the importance of BLEU, METEOR, ROUGE, CIDEr, and SPICE metrics in determining the caliber of created captions. This study is an invaluable tool for scholars and practitioners looking to improve the field because it offers a thorough analysis of the developments and difficulties in this field. To be more precise, we start by quickly going over the earlier traditional works using the retrieval and template. After that, research on deep learning (DL)-based image captioning is concentrated. For a thorough overview, these studies are divided into three categories: the encoder-decoder architecture, the attention techniques, and training techniques based on framework structures and training methods. The publicly accessible datasets, evaluation metrics, and those suggested for particular requirements are then summarized, and the state-of-the-art techniques are then contrasted using the MS COCO dataset, we offer a few talks about unresolved issues and potential avenues for future research.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
IJCERT Policy:
The published work presented in this paper is licensed under the Creative Commons Attribution 4.0 International (CC BY 4.0) license. This means that the content of this paper can be shared, copied, and redistributed in any medium or format, as long as the original author is properly attributed. Additionally, any derivative works based on this paper must also be licensed under the same terms. This licensing agreement allows for broad dissemination and use of the work while maintaining the author's rights and recognition.
By submitting this paper to IJCERT, the author(s) agree to these licensing terms and confirm that the work is original and does not infringe on any third-party copyright or intellectual property rights.




References
K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y. Bengio, “Show, attend and tell: Neural image caption generation with visual attention,” in Proc. Int. Conf. Machine Learning, 2015, pp. 2048−2057
O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: Lessons learned from the 2015 MS COCO image captioning challenge,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol.39, no.4, pp.652–663, 2016.
J. Lu, C. Xiong, D. Parikh, and R. Socher, “Knowing when to look: Adaptive attention via a visual sentinel for image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2017, pp. 375−383.
S. J. Rennie, E. Marcheret, Y. Mroueh, J. Ross, and V. Goel, “Selfcritical sequence training for image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2017, pp. 7008− 7024.
W. Liu, S. Chen, L. Guo, X. Zhu, and J. Liu, “CPTR: Full transformer network for image captioning,” arXiv preprint arXiv: 2101.10804, 2021.
T. Yao, Y. Pan, Y. Li, and T. Mei, “Exploring visual relationship for image captioning,” in Proc. European Conf. Computer Vision, 2018, pp. 684−699.
L. Guo, J. Liu, J. Tang, J. Li, W. Luo, and H. Lu, “Aligning linguistic words and visual semantic units for image captioning,” in Proc. 27th ACM Int. Conf. Multimedia, 2019, pp. 765−773.
J. Yu, J. Li, Z. Yu, and Q. Huang, “Multimodal transformer with multi-view visual representation for image captioning,” IEEE Trans. Circuits and Systems for Video Technology, vol.30, no. 12, pp. 4467– 4480, 2020.
P. Zhang, X. Li, X. Hu, J. Yang, L. Zhang, L. Wang, Y. Choi, and J. Gao, “VINVL: Revisiting visual representations in vision-language models,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2021, pp. 5579−5588.
X. Zhang, X. Sun, Y. Luo, J. Ji, Y. Zhou, Y. Wu, F. Huang, and R. Ji, “Rstnet: Captioning with adaptive attention on visual and non-visual words,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2021, pp. 15465−15474.
X. Yang, K. Tang, H. Zhang, and J. Cai, “Auto-encoding scene graphs for image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019, pp. 10685−10694.
X. Yang, H. Zhang, and J. Cai, “Learning to collocate neural modules for image captioning,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2019, pp. 4250−4260
J. Gu, J. Cai, G. Wang, and T. Chen, “Stack-captioning: Coarse-to-fine learning for image captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2018, vol. 32, no. 1, pp. 6837–6844
L. Li, S. Tang, L. Deng, Y. Zhang, and Q. Tian, “Image caption with global-local attention,” in Proc. AAAI Conf. Artificial Intelligence, 2017, vol. 31, no. 1, pp. 4133−4239.
M. Cornia, L. Baraldi, G. Serra, and R. Cucchiara, “Paying more attention to saliency: Image captioning with saliency and context attention,” ACM Trans. Multimedia Computing, Communications, and Applications, vol.14, no.2, pp.1–21, 2018.
L. Gao, K. Fan, J. Song, X. Liu, X. Xu, and H. T. Shen, “Deliberate attention networks for image captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2019, vol. 33, no. 1, pp. 8320−8327.
Z. Zhang, Q. Wu, Y. Wang, and F. Chen, “Exploring region relationships implicitly: Image captioning with visual relationship attention,” Image and Vision Computing, vol. 109, p. 104146, 2021. DOI: 10.1016/j.imavis.2021.104146.
Y. Pan, T. Yao, Y. Li, and T. Mei, “X-linear attention networks for image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2020, pp. 10971−10980.
S. Herdade, A. Kappeler, K. Boakye, and J. Soares, “Image captioning: Transforming objects into words,” in Proc. Advances in Neural Information Processing Systems, 2019, pp. 11137−11147.
L. Guo, J. Liu, X. Zhu, P. Yao, S. Lu, and H. Lu, “Normalized and geometry-aware self-attention network for image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2020, pp. 10327−10336.
G. Li, L. Zhu, P. Liu, and Y. Yang, “Entangled transformer for image captioning,” in Proc. IEEE Int. Conf. Computer Vision, 2019, pp. 8928−8937.
M. Cornia, M. Stefanini, L. Baraldi, and R. Cucchiara, “Meshed memory transformer for image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2020, pp. 10578−10587.
X. Li, X. Yin, C. Li, P. Zhang, X. Hu, L. Zhang, L. Wang, H. Hu, L. Dong, F. Wei, et al., “Oscar: Object-semantics aligned pre-training for vision-language tasks,” in Proc. European Conf. Computer Vision, Springer, 2020, pp. 121−137
Y. Qin, J. Du, Y. Zhang, and H. Lu, “Look back and predict forward in image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019, pp. 8367−8375.
Y. Luo, J. Ji, X. Sun, L. Cao, Y. Wu, F. Huang, C.-W. Lin, and R. Ji, “Dual-level collaborative transformer for image captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2021, vol. 35, no. 3, pp. 2286−2293.
Z. Shi, X. Zhou, X. Qiu, and X. Zhu, “Improving image captioning with better use of caption,” in Proc. 58th Annual Meeting Association for Computational Linguistics, 2020, pp. 7454−7464.
L. Huang, W. Wang, J. Chen, and X. Wei, “Attention on attention for image captioning,” in Proc. IEEE Int. Conf. Computer Vision, 2019, pp. 4634−4643.
D. Liu, Z.-J. Zha, H. Zhang, Y. Zhang, and F. Wu, “Context-aware visual policy network for sequence-level image captioning,” in Proc. 26th ACM Int. Conf. Multimedia, 2018, pp. 1416−1424.
W. Jiang, L. Ma, Y.-G. Jiang, W. Liu, and T. Zhang, “Recurrent fusion network for image captioning,” in Proc. European Conf. Computer Vision, Springer, 2018, pp. 499−515.
T. Yao, Y. Pan, Y. Li, Z. Qiu, and T. Mei, “Boosting image captioning with attributes,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2017, pp. 4894−4902.
T. Yao, Y. Pan, Y. Li, and T. Mei, “Hierarchy parsing for image captioning,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2019, pp. 2621−2629.
Y. Zhou, M. Wang, D. Liu, Z. Hu, and H. Zhang, “More grounded image captioning by distilling image-text matching model,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2020, pp. 4777−4786.
L. Wang, Z. Bai, Y. Zhang, and H. Lu, “Show, recall, and tell: Image captioning with recall mechanism.” in Proc. AAAI Conf. Artificial Intelligence, 2020, pp. 12176−12183.
J. Ji, Y. Luo, X. Sun, F. Chen, G. Luo, Y. Wu, Y. Gao, and R. Ji, “Improving image captioning by leveraging intra-and inter-layer global representation in transformer network,” in Proc. AAAI Conf. Artificial Intelligence, 2021, vol. 35, no. 2, pp. 1655−1663.
Papineni, K., Roukos, S., Ward, T., & Zhu, W. (2002). BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics.
Lin, C. Y. (2004). ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out.
Banerjee, S., & Lavie, A. (2005). METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization.
Vedantam, R., Zitnick, C. L., & Parikh, D. (2015). CIDEr: Consensus-based Image Description Evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Anderson, P., He, X., Buehler, C., Teney, D., Johnson, M., Gould, S., & Zhang, L. (2016). SPICE: Semantic Propositional Image Caption Evaluation. In ECCV.
Brown, P. F., Pietra, V. J. D., Pietra, S. A. D., & Mercer, R. L. (1993). The mathematics of statistical machine translation: Parameter estimation. In Computational Linguistics, 19(2), 263-311.
Dolan, W. B., Quirk, C., & Brockett, C. (2004). Unsupervised Construction of Large Paraphrase Corpora: Exploiting Massively Parallel News Sources. In Proceedings of the 20th International Conference on Computational Linguistics.
Elliott, D., & Keller, F. (2013). Image Description Using Visual Dependency Representations. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).
Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., ... & Zitnick, C. L. (2014). Microsoft COCO: Common Objects in Context. In European Conference on Computer Vision.
Young, P., Lai, A., Hodosh, M., & Hockenmaier, J. (2014). From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. In Transactions of the Association for Computational Linguistics.
Rashtchian, C., Young, P., Hodosh, M., & Hockenmaier, J. (2010). Collecting image annotations using Amazon's Mechanical Turk. In Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon's Mechanical Turk.
Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, J., ... & Fei-Fei, L. (2017). Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. International Journal of Computer Vision, 123(1), 32-73.
Sariyildiz, I. S., Yuret, D., & Karakaya, K. (2019). AI2D: A Large-scale Dataset for Denotational Image Description. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
M. Everingham, A. Zisserman, C. K. Williams, et al., “The 2005 pascal visual object classes challenge,” in Proc. Machine Learning Challenges Workshop, Springer, 2005, pp. 117−176.
B. Thomee, D. A. Shamma, G. Friedland, B. Elizalde, K. Ni, D. Poland, D. Borth, and L.-J. Li, “YFCC100m: The new data in multimedia research,” Commun. ACM, vol. 59, no. 2, pp. 64–73, 2016.
D. Elliott, S. Frank, K. Sima’an, and L. Specia, “Multi30k: Multil- ingual english-german image descriptions,” in Proc. 5th Workshop on Vision and Language, 2016, pp. 70−74.
J. Wu, H. Zheng, B. Zhao, Y. Li, B. Yan, R. Liang, W. Wang, S. Zhou, G. Lin, Y. Fu, Y. Z. Wang, and Y. G. Wang, “AI challenger: A large- scale dataset for going deeper in image understanding,” arXiv preprint arXiv: 1711.06475, 2017.
M. Grubinger, P. Clough, H. Müller, and T. Deselaers, “The iapr TC-12 benchmark: A new evaluation resource for visual information systems,” in Proc. Int. Workshop OntoImage, 2006, vol. 2, pp.13–23.
F. Biten, L. Gomez, M. Rusinol, and D. Karatzas, “Good news, everyone! Context driven entity-aware captioning for news images,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019, pp. 12466−12475.
D. Gurari, Y. Zhao, M. Zhang, and N. Bhattacharya, “Captioning images taken by people who are blind,” in Proc. European Conf. Computer Vision, Springer, 2020, pp. 417−434.
H. Agrawal, K. Desai, Y. Wang, X. Chen, R. Jain, M. Johnson, D. Batra, D. Parikh, S. Lee, and P. Anderson, “NOCAPS: Novel object captioning at scale,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2019, pp. 8948−8957.
X. Yang, H. Zhang, D. Jin, Y. Liu, C.-H. Wu, J. Tan, D. Xie, J. Wang, and X. Wang, “Fashion captioning: Towards generating accurate descriptions with semantic rewards,” in Proc. Computer Vision-ECCV, Springer, 2020, pp. 1−17.
O. Sidorov, R. Hu, M. Rohrbach, and A. Singh, “Textcaps: A dataset for image captioning with reading comprehension,” in Proc. European Conf. Computer Vision, Springer, 2020, pp. 742−758