
Enhancing Image Descriptions with Image Transformers: A Journey into Advanced Image Captioning
Article Sidebar
Main Article Content
Abstract
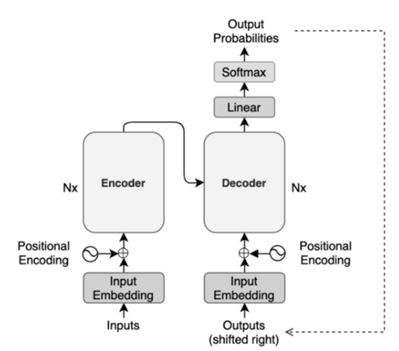
This research investigates using Image Transformers to improve image captioning. Deep learning algorithms have improved image captioning. We use Image Transformers, a sophisticated neural network design that captures intricate visual aspects and interactions in images, to improve image captioning. This study describes the creation and implementation of our innovative image captioning system, which seamlessly integrates Image Transformers with classic captioning structures. We show significant advances in visual description accuracy and contextually through trials and evaluations. This method improves image-caption correspondence by providing more exact and meaningful captions and a greater grasp of the visual material. This research has many applications, including visual impairment accessibility, media and marketing content development, and more. This study shows how Image Transformers might alter image captioning and usher in a new era of immersive and context-aware human-machine interaction.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
IJCERT Policy:
The published work presented in this paper is licensed under the Creative Commons Attribution 4.0 International (CC BY 4.0) license. This means that the content of this paper can be shared, copied, and redistributed in any medium or format, as long as the original author is properly attributed. Additionally, any derivative works based on this paper must also be licensed under the same terms. This licensing agreement allows for broad dissemination and use of the work while maintaining the author's rights and recognition.
By submitting this paper to IJCERT, the author(s) agree to these licensing terms and confirm that the work is original and does not infringe on any third-party copyright or intellectual property rights.




References
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. ArXiv: 1810.04805.
Clark, K., Luong, M.-T., Le, Q. V., & Manning, C. D. (2020). ELECTRA: pre-training text encoders as discriminators rather than generators. International Conference on Learning Representations.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. ArXiv, abs/1907.11692.
Beltagy, I., Peters, M. E., & Cohan, A. (2020). Longformer: the long-document transformer. ArXiv: 2004.05150.
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T.J., Child, R., Ramesh, A., Ziegler, D.M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., & Amodei, D. (2020). Language Models are Few-Shot Learners. ArXiv, abs/2005.14165.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 9.
Bao, Y., Sivanandan, S., & Karaletsos, T. (2023). Channel Vision Transformers: An Image Is Worth C x 16 x 16 Words. ArXiv, abs/2309.16108.
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., & Guo, B. (2021). Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 9992-10002.
Gulati, A., Qin, J., Chiu, C., Parmar, N., Zhang, Y., Yu, J., Han, W., Wang, S., Zhang, Z., Wu, Y., & Pang, R. (2020). Conformer: Convolution-augmented Transformer for Speech Recognition. ArXiv, abs/2005.08100.
Chen, L., Lu, K., Rajeswaran, A., Lee, K., Grover, A., Laskin, M., Abbeel, P., Srinivas, A., & Mordatch, I. (2021). Decision Transformer: Reinforcement Learning via Sequence Modeling. Neural Information Processing Systems.
Dwivedi, V. P., & Bresson, X. (2020). A generalization of transformer networks to graphs. ArXiv: 2012.09699.
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. ArXiv: 1409.0473.
Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. Advances in Neural Information Processing Systems (pp. 3104–3112).
Kiros, R., Salakhutdinov, R. and Zemel, R., Multimodal neural language models. In International conference on machine learning, 2014, June. (pp. 595-603). PMLR
Fu, K., Jin, J., Cui, R., Sha, F. and Zhang, C., Aligning where to see and what to tell: Image captioning with region-based attention and scene-specific contexts. IEEE transactions on pattern analysis and machine intelligence, 39(12), 2016, pp.2321-2334.
Karpathy, A. and Fei-Fei, L., Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, (pp. 3128-3137).
Karpathy, A., Joulin, A. and Fei-Fei, L., Deep fragment embeddings for bidirectional image sentence mapping. arXiv preprint arXiv:1406.5679, 2014.
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., Zemel, R. and Bengio, Y., Show, attend and tell: Neural image caption generation with visual attention. In International conference on machine learning, 2015, June, (pp. 2048- 2057). PMLR.
Wang, Y., Lin, Z., Shen, X., Cohen, S. and Cottrell, G.W., Skeleton key: Image captioning by skeleton-attribute decomposition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, (pp. 7272-7281
Zhao, W., Wang, B., Ye, J., Yang, M., Zhao, Z., Luo, R. and Qiao, Y., A Multi-task Learning Approach for Image Captioning. In IJCAI , 2018, July, (pp. 1205-1211)
Yu, J., Li, J., Yu, Z. and Huang, Q., Multimodal transformer with multi-view visual representation for image captioning. IEEE transactions on circuits and systems for video technology, 30(12), 2019, pp.4467-4480.
Tran, K., He, X., Zhang, L., Sun, J., Carapcea, C., Thrasher, C., Buehler, C. and Sienkiewicz, C., Rich image captioning in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 2016. pp. 49- 56
Fang, H., Gupta, S., Iandola, F., Srivastava, R.K., Deng, L., Dollár, P., Gao, J., He, X., Mitchell, M., Platt, J.C. and Lawrence Zitnick, C., From captions to visual concepts and back. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, (pp. 1473-1482).
Ma, S. and Han, Y. Describing images by feeding LSTM with structural words. In 2016 IEEE International Conference on Multimedia and Expo (ICME), 2016, July, (pp. 1-6). IEEE.
Oruganti, R.M., Sah, S., Pillai, S. and Ptucha, R., Image description through fusion based recurrent multi-modal learning. In 2016 IEEE International Conference on Image Processing (ICIP), 2016, September, (pp. 3613-3617). IEEE.
Wang, M., Song, L., Yang, X. and Luo, C.,. A parallel-fusion RNN-LSTM architecture for image caption generation. In 2016 IEEE International Conference on Image Processing (ICIP), 2016, September, (pp. 4448-4452). IEEE
Kulkarni, G., Premraj, V., Ordonez, V., Dhar, S., Li, S., Choi, Y., Berg, A.C. and Berg, T.L., Babytalk: Understanding and generating simple image descriptions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(12), 2013, pp.2891-2903
Mao, J., Xu, W., Yang, Y., Wang, J. and Yuille, A.L., Explain images with multimodal recurrent neural networks. arXiv preprint arXiv:1410.1090, 2014.
Chen, X. and Lawrence Zitnick, C., Mind's eye: A recurrent visual representation for image caption generation. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, (pp. 2422-2431).
Gan, Z., Gan, C., He, X., Pu, Y., Tran, K., Gao, J., Carin, L. and Deng, L., Semantic compositional networks for visual captioning. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, (pp. 5630-5639).
Yao, T., Pan, Y., Li, Y., Qiu, Z. and Mei, T., Boosting image captioning with attributes. In Proceedings of the IEEE International Conference on Computer Vision, 2017, (pp. 4894-4902).
Mao, J., Wei, X., Yang, Y., Wang, J., Huang, Z. and Yuille, A.L., Learning like a child: Fast novel visual concept learning from sentence descriptions of images. In Proceedings of the IEEE international conference on computer vision, 2015, (pp. 2533-2541).
Hendricks, L.A., Venugopalan, S., Rohrbach, M., Mooney, R., Saenko, K. and Darrell, T., Deep compositional captioning: Describing novel object categories without paired training data. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, (pp. 1-10).
Venugopalan, S., Anne Hendricks, L., Rohrbach, M., Mooney, R., Darrell, T. and Saenko, K., Captioning images with diverse objects. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, (pp. 5753-5761).
Mathews, A., Xie, L. and He, X., Senticap: Generating image descriptions with sentiments. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 30, No. 1), 2016, March
Nezami, O.M., Dras, M., Anderson, P. and Hamey, L., Face-cap: Image captioning using facial expression analysis. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, 2018, September, (pp. 226- 240). Springer, Cham.
Chunseong Park, C., Kim, B. and Kim, G., Attend to you: Personalized image captioning with context sequence memory networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, (pp. 895-903).
Liu, A., Xu, N., Zhang, H., Nie, W., Su, Y. and Zhang, Y., Multi-Level Policy and Reward Reinforcement Learning for Image Captioning. In IJCAI, 2018, January, (pp. 821-827).
Cornia, M., Stefanini, M., Baraldi, L. and Cucchiara, R., Meshed-memory transformer for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, (pp. 10578-10587).
Johnson, J., Karpathy, A. and Fei-Fei, L., Densecap: Fully convolutional localization networks for dense captioning. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, (pp. 4565-4574).
Yang, L., Tang, K., Yang, J. and Li, L.J., Dense captioning with joint inference and visual context. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, (pp. 2193-2202)
Chun, S., Kim, W., Park, S., Chang, M., & Oh, S. (2022). ECCV Caption: Correcting False Negatives by Collecting Machine-and-Human-verified Image-Caption Associations for MS-COCO. European Conference on Computer Vision.
Papineni, K., Roukos, S., Ward, T., & Zhu, W. (2002). BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics (ACL), (pp. 311-318).
Lavie, A., & Agarwal, A. (2007). METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, (pp. 65-72).
Lin, C. Y. (2004). ROUGE: A package for automatic evaluation of summaries. In Proceedings of the Workshop on Text Summarization Branches Out, (pp. 74-81).
Vedantam, R., Zitnick, C. L., & Parikh, D. (2015). CIDEr: Consensus-based image description evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), (pp. 4566-4575).
Liu, F., Ren, X., Liu, Y., Lei, K. and Sun, X., Exploring and distilling cross-modal information for image captioning. arXiv preprint arXiv:2002.12585, 2020.
Yao, T., Pan, Y., Li, Y. and Mei, T., Hierarchy parsing for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, (pp. 2621-2629).
Vinyals, O., Toshev, A., Bengio, S. and Erhan, D., Show and tell: A neural image caption generator. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, (pp. 3156-3164).
Jia, X., Gavves, E., Fernando, B. and Tuytelaars, T., Guiding the long-short term memory model for image caption generation. In Proceedings of the IEEE international conference on computer vision, 2015, (pp. 2407-2415).
Fang, H., Gupta, S., Iandola, F., Srivastava, R.K., Deng, L., Dollár, P., Gao, J., He, X., Mitchell, M., Platt, J.C. and Lawrence Zitnick, C., From captions to visual concepts and back. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, (pp. 1473-1482).
You, Q., Jin, H., Wang, Z., Fang, C. and Luo, J.,. Image captioning with semantic attention. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, (pp. 4651-4659).
Yao, T., Pan, Y., Li, Y., Mei, T.: Exploring visual relationship for image captioning. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) Computer Vision – ECCV 2018. LNCS, vol. 11218, pp. 711–727. Springer, Cham (2018). https://doi. org/10.1007/978-3-030-01264-9 42
Yang, X., Tang, K., Zhang, H., Cai, J.: Auto-encoding scene graphs for image captioning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 10685–10694 (2019)
Guo, L., Liu, J., Tang, J., Li, J., Luo, W., Lu, H.: Aligning linguistic words and visual semantic units for image captioning. In: Proceedings of the 27th ACM International Conference on Multimedia, pp. 765–773 (2019)
Yao, T., Pan, Y., Li, Y., Mei, T.: Hierarchy parsing for image captioning. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2621– 2629 (2019)
Li, G., Zhu, L., Liu, P., Yang, Y.: Entangled transformer for image captioning. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 8928–8937 (2019)
Huang, L., Wang, W., Chen, J., Wei, X.Y.: Attention on attention for image captioning. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 4634–4643 (2019)