
Minimizing Errors in Air Traffic Speech Using Rule Based Algorithms
Article Sidebar
Main Article Content
Abstract
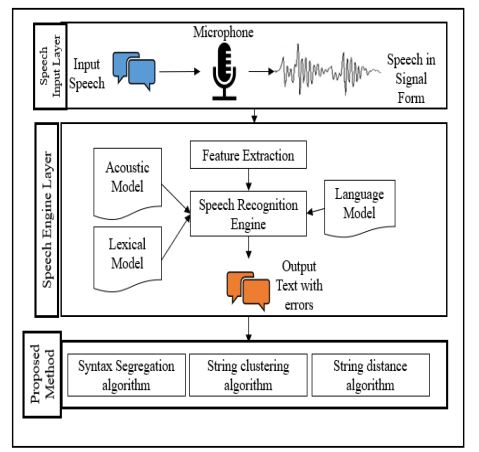
The application of automatic speech recognition for air traffic speech has attracted a lot of attention in recent times. The application of machine learning and deep learning models can address the challenges of speech recognition to some extent. This work focuses on understanding the intricacies of domain characteristics and how to leverage them to improve speech recognition.This work focuses on applying rule-based techniques in the postprocessing phase of speech recognition. The post-processing stage is defined as
a stage where a set of algorithms are applied to the decoded output of speech recognition. Multiple techniques, like syntax separation techniques, co-occurrence-based clustering techniques, and string distance algorithms, are discussed in this work. The choice of these algorithms is based on an understanding of the significance of air traffic speech domain characteristics. Machine learning and deep learning models were applied in feature selection, language model generation, or acoustic model generation. Approaches based on rules could be selectively applied as an incremental update to language models or acoustic model generation. This work was able to improve the accuracy by 9% by applying selective algorithms for error detection and correction. Comparisons of different techniques were discussed when multiple techniques were used for clustering and string distance calculations. One of the good observations of this work is that leveraging the characteristics of speech in this domain helped improve accuracy. The improvement in accuracy was
seen in two scenarios. One scenario has a complete utterance, and the other scenario has syntax-separated utterances. A rule-based algorithm was proposed for syntax separation.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
IJCERT Policy:
The published work presented in this paper is licensed under the Creative Commons Attribution 4.0 International (CC BY 4.0) license. This means that the content of this paper can be shared, copied, and redistributed in any medium or format, as long as the original author is properly attributed. Additionally, any derivative works based on this paper must also be licensed under the same terms. This licensing agreement allows for broad dissemination and use of the work while maintaining the author's rights and recognition.
By submitting this paper to IJCERT, the author(s) agree to these licensing terms and confirm that the work is original and does not infringe on any third-party copyright or intellectual property rights.




References
Cordero, J.M., Rodríguez, N.D., Miguel, J., Pablo, D., & Crida (2013). Automated Speech Recognition in Controller Communications applied to Workload Measurement.
Oualil, Y., M. Schulder, H. Helmke, A. Schmidt, & D. Klakow. (2015). Real-Time Integration of Dynamic Context Information for Improving Automatic Speech Recognition. 2107–2111.
Nguyen V., & H. Holone. (2016). N-best list re-ranking using syntactic score: A solution for improving speech recognition accuracy in air traffic control. 1309–1314.
Srinivasamurthy, A., P. Motlicek, I. Himawan, G. Szaszák, Y. Oualil, & H. Helmke. (2017). Semi-supervised Learning with Semantic Knowledge Extraction for Improved Speech Recognition in Air Traffic Control. 2017, 2406–2410
Pardo, J. M., J. Ferreiros, V. Sama, R. de Cordoba, J. Macias-Guarasa, J. M. Montero, R. San-Segundo, L. F. D’Haro, G. Gonzalez. (2011). Automatic Understanding of ATC Speech: Study of Prospectives and Field Experiments for Several Controller Positions. IEEE Transactions on Aerospace and Electronic Systems, 47(4), 2709–2730.
Badrinath, S., & B, Hasini. (2021). Automatic Speech Recognition for Air Traffic Control Communications. Transportation Research Record, 036119812110363.
Oualil, Y., M. Schulder, H. Helmke, A. Schmidt, & D. Klakow. (2015). Real-Time Integration of Dynamic Context Information for Improving Automatic Speech Recognition. 2107–2111.
Nguyen V., & H. Holone. (2016). N-best list re-ranking using semantic relatedness and syntactic score: An approach for improving speech recognition accuracy in air traffic control. International Conference on Control, Automation and Systems, 1315–1319.
Srinivasamurthy, A., Motlicek, P., Singh, M., Oualil, Y., Kleinert, M., Ehr, H., & Helmke, H. (2018). Iterative Learning of Speech Recognition Models for Air Traffic Control. Interspeech, 3519–3523.
Chen S, H. D. Kopald, R. Chong, D. Wei, & Z. Levonian. (2017). Read Back Error Detection using Automatic Speech Recognition.