
Comparative Analysis of Feature Extraction Techniques and Machine Learning Models for Twitter Text Classification
Article Sidebar
Main Article Content
Abstract
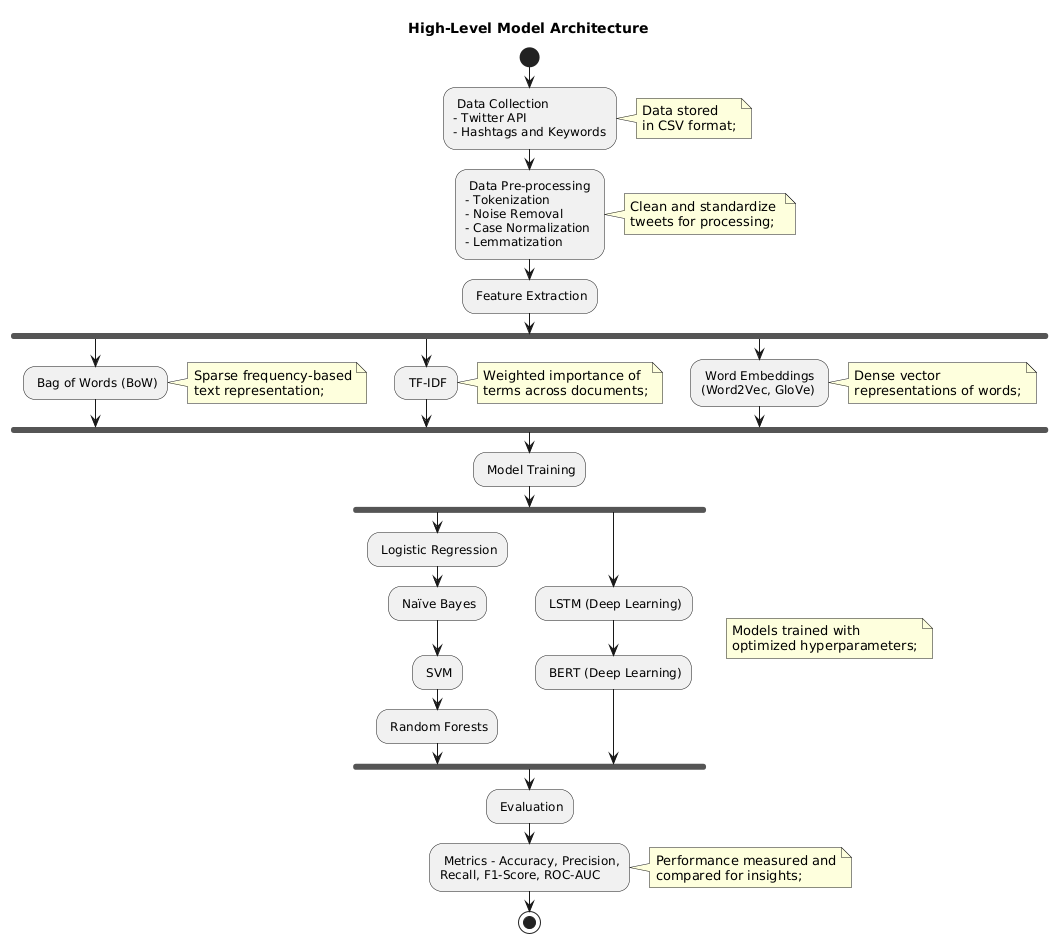
The rapid growth of Twitter as a platform for sharing opinions and information has made it a valuable resource for text classification tasks such as sentiment analysis and trend detection. However, the unstructured and noisy nature of tweets poses significant challenges, necessitating advanced techniques for effective classification. This research systematically evaluates the performance of traditional and deep learning models in combination with three feature extraction methods: Bag of Words (BoW), Term Frequency-Inverse Document Frequency (TF-IDF), and Word Embeddings (Word2Vec, GloVe). Six machine learning models, including Logistic Regression, Naïve Bayes, Support Vector Machines (SVM), Random Forests, Long Short-Term Memory Networks (LSTM), and BERT, were assessed using standard metrics such as accuracy, precision, recall, F1-score, and ROC-AUC. Results indicate that Word Embeddings, particularly when paired with BERT, achieve the highest accuracy and precision, while TF-IDF with SVM offers competitive performance for resource-constrained scenarios. The study highlights the trade-offs between computational efficiency and performance, providing insights into selecting suitable techniques for practical applications. These findings contribute to advancing text classification methods for social media data and offer a foundation for future research in scalable and efficient NLP systems.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
IJCERT Policy:
The published work presented in this paper is licensed under the Creative Commons Attribution 4.0 International (CC BY 4.0) license. This means that the content of this paper can be shared, copied, and redistributed in any medium or format, as long as the original author is properly attributed. Additionally, any derivative works based on this paper must also be licensed under the same terms. This licensing agreement allows for broad dissemination and use of the work while maintaining the author's rights and recognition.
By submitting this paper to IJCERT, the author(s) agree to these licensing terms and confirm that the work is original and does not infringe on any third-party copyright or intellectual property rights.




References
A. Pak and P. Paroubek, "Twitter as a corpus for sentiment analysis and opinion mining," Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC'10), 2010, pp. 1320–1326.
B. Pang and L. Lee, "Opinion mining and sentiment analysis," Foundations and Trends in Information Retrieval, vol. 2, no. 1-2, pp. 1–135, 2008.
T. Mikolov, K. Chen, G. Corrado, and J. Dean, "Efficient estimation of word representations in vector space," arXiv preprint arXiv: 1301.3781, 2013.
J. Pennington, R. Socher, and C. D. Manning, "GloVe: Global vectors for word representation," Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014, pp. 1532–1543.
T. Joachims, "Text categorization with support vector machines: Learning with many relevant features," Proceedings of the European Conference on Machine Learning (ECML), 1998, pp. 137–142.
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, "BERT: Pre-training of deep bidirectional transformers for language understanding," arXiv preprint arXiv: 1810.04805, 2018.
A. Kouloumpis, T. Wilson, and J. Moore, "Twitter sentiment analysis: The good the bad and the omg!," Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media (ICWSM), 2011, pp. 538–541.
R. Johnson and T. Zhang, "Effective use of word order for text categorization with convolutional neural networks," Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2015, pp. 103–112.
S. Hochreiter and J. Schmidhuber, "Long short-term memory," Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.
Y. Kim, "Convolutional neural networks for sentence classification," Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014, pp. 1746–1751.
A. Bifet and E. Frank, "Sentiment knowledge discovery in Twitter streaming data," Proceedings of the 13th International Conference on Discovery Science (DS), 2010, pp. 1–15
S. Asur and B. A. Huberman, "Predicting the future with social media," Proceedings of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), 2010, pp. 492–499.
J. Ramos, "Using TF-IDF to determine word relevance in document queries," Proceedings of the First Instructional Conference on Machine Learning (iCML), 2003, pp. 133–142.
Q. Le and T. Mikolov, "Distributed representations of sentences and documents," Proceedings of the 31st International Conference on Machine Learning (ICML), 2014, pp. 1188–1196.
K. Cho et al., "Learning phrase representations using RNN encoder-decoder for statistical machine translation," Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014, pp. 1724–1734.
S. Wu and M. Dredze, “Beto, Bentz, becas: The surprising cross-lingual effectiveness of BERT,” arXiv [cs.CL], 2019.
H. Almeida, D. Mozetic, M. Grcar, and M. Smailovic, "Sentiment analysis and the impact of employee satisfaction on company financial performance," PLoS ONE, vol. 12, no. 11, p. e0187666, 2017.
J. Yang, J. Carbonell, R. D. Brown, and W. S. Noble, "Multi-task learning and empirical Bayes methods for predicting protein secondary structure," Proceedings of the 25th International Conference on Machine Learning (ICML), 2008, pp. 1048–1055.
R. A. Fisher, "The use of multiple measurements in taxonomic problems," Annals of Eugenics, vol. 7, no. 2, pp. 179–188, 1936. (For Logistic Regression)
G. H. John and P. Langley, "Estimating continuous distributions in Bayesian classifiers," Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence (UAI), 1995, pp. 338–345. (For Naïve Bayes)
T. Joachims, "Text categorization with support vector machines: Learning with many relevant features," Proceedings of the European Conference on Machine Learning (ECML), 1998, pp. 137–142. (For Support Vector Machines)
L. Breiman, "Random forests," Machine Learning, vol. 45, no. 1, pp. 5–32, 2001. (For Random Forests)
S. Hochreiter and J. Schmidhuber, "Long short-term memory," Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997. (For LSTM)
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, "BERT: Pre-training of deep bidirectional transformers for language understanding," arXiv preprint arXiv: 1810.04805, 2018. (For BERT)