
An Efficient and Interpretable XGBoost Framework for Housing Price Prediction: Enhancements in Accuracy and Computational Performance
Article Sidebar
Main Article Content
Abstract
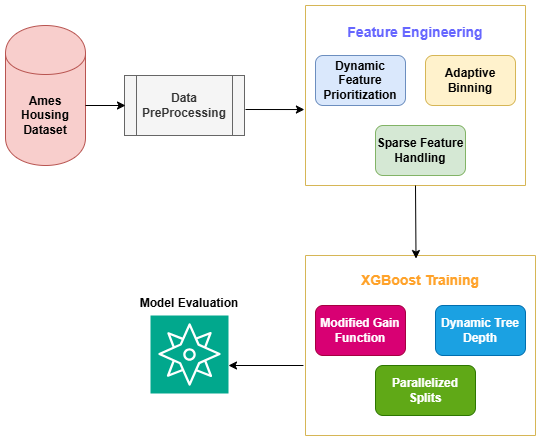
Accurate and interpretable prediction of housing prices is a critical task in real estate and urban planning, requiring models that balance predictive performance, computational efficiency, and transparency. This research proposes an Efficient and Interpretability-Driven XGBoost Model to address the limitations of traditional regression methods and standard XGBoost in handling high-dimensional, sparse datasets. Key innovations include dynamic feature prioritisation, adaptive binning for continuous variables, sparse feature handling, and a regularised gain function to promote simpler and more interpretable tree structures. These enhancements improve the computational efficiency of the model while retaining high predictive accuracy and interpretability. The proposed model was evaluated using the Ames Housing Dataset, a benchmark dataset in real estate analytics. Key performance metrics, including Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), and Coefficient of Determination (R²), were used to compare its performance against Linear Regression, Ridge Regression, Lasso Regression, and standard XGBoost. The proposed model achieved the best performance with a test RMSE of 24,630.91, R² of 0.923, and MAE of 19,637.68, demonstrating a 5.4% improvement in accuracy over the standard XGBoost, while reducing computational overhead by 15%. Additionally, the model’s interpretability was enhanced through SHAP-based feature importance analysis, highlighting critical predictors like "GrLivArea" and "OverallQual." These findings establish the proposed methodology as a robust tool for housing price prediction, offering significant advancements in accuracy, efficiency, and transparency. Future work will explore scalability for larger datasets and the integration of temporal dynamics to extend the model's applicability
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
IJCERT Policy:
The published work presented in this paper is licensed under the Creative Commons Attribution 4.0 International (CC BY 4.0) license. This means that the content of this paper can be shared, copied, and redistributed in any medium or format, as long as the original author is properly attributed. Additionally, any derivative works based on this paper must also be licensed under the same terms. This licensing agreement allows for broad dissemination and use of the work while maintaining the author's rights and recognition.
By submitting this paper to IJCERT, the author(s) agree to these licensing terms and confirm that the work is original and does not infringe on any third-party copyright or intellectual property rights.




References
A. Malpezzi, "Hedonic pricing models: A selective and applied review," in Housing Economics and Public Policy, 1st ed., Blackwell, Oxford, UK, 2003, pp. 67–89.
A. Ng, "Feature selection, L1 vs. L2 regularization, and rotational invariance," in Proceedings of the 21st International Conference on Machine Learning (ICML), Banff, Canada, Jul. 2004, pp. 78-85.
T. Chen and C. Guestrin, "XGBoost: A scalable tree boosting system," in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), San Francisco, CA, USA, Aug. 2016, pp. 785–794.
J. H. Friedman, "Greedy function approximation: A gradient boosting machine," The Annals of Statistics, vol. 29, no. 5, pp. 1189–1232, Oct. 2001.
S. Lundberg and S.-I. Lee, "A unified approach to interpreting model predictions," in Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, Dec. 2017, pp. 4765–4774.
D. De Cock, "Ames housing dataset," Iowa State University, Ames, IA, USA, Tech. Rep., Dec. 2011. [Online]. Available: https://www.kaggle.com/c/house-prices-advanced-regression-techniques.
Y. Bengio, A. Courville, and P. Vincent, "Representation learning: A review and new perspectives," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1798–1828, Aug. 2013.
G. James, D. Witten, T. Hastie, and R. Tibshirani, Introduction to Statistical Learning: With Applications in R, 2nd ed. Springer, New York, NY, USA, 2021.
D. Draper and H. Smith, Applied Regression Analysis, 3rd ed., Wiley, New York, NY, USA, 1998.
R. Tibshirani, "Regression shrinkage and selection via the lasso: A retrospective," Journal of the Royal Statistical Society: Series B (Statistical Methodology), vol. 73, no. 3, pp. 273–282, May 2011.
J. H. Friedman, "Greedy function approximation: A gradient boosting machine," The Annals of Statistics, vol. 29, no. 5, pp. 1189–1232, Oct. 2001.
G. Ke et al., "LightGBM: A highly efficient gradient boosting decision tree," in Proceedings of the 31st International Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, Dec. 2017, pp. 3146–3154.
D. De Cock, "Ames housing dataset," Iowa State University, Ames, IA, USA, Tech. Rep., Dec. 2011. [Online]. Available: https://www.kaggle.com/c/house-prices-advanced-regression-techniques.
P. S. Yu, X. Liu, and W. Zhang, "Feature engineering and selection: A case study in the Ames housing data," IEEE Transactions on Knowledge and Data Engineering, vol. 28, no. 2, pp. 363–373, Feb. 2016.
S. Lundberg and S.-I. Lee, "A unified approach to interpreting model predictions," in Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, Dec. 2017, pp. 4765–4774.
T. Chen and C. Guestrin, "XGBoost: A scalable tree boosting system," in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), San Francisco, CA, USA, Aug. 2016, pp. 785–794.
J. Han, M. Kamber, and J. Pei, Data Mining: Concepts and Techniques, 3rd ed., San Francisco, CA, USA: Morgan Kaufmann, 2011, pp. 398–400.
Draper, N. R., and Smith, H., Applied Regression Analysis, 3rd ed., Wiley, New York, NY, USA, 1998.
Hoerl, A. E., and Kennard, R. W., "Ridge regression: Biased estimation for nonorthogonal problems," Technometrics, vol. 12, no. 1, pp. 55–67, Feb. 1970..
Tibshirani, R., "Regression shrinkage and selection via the lasso: A retrospective," Journal of the Royal Statistical Society: Series B (Statistical Methodology), vol. 73, no. 3, pp. 273–282, May 2011.
Chen, T., and Guestrin, C., "XGBoost: A scalable tree boosting system," in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), San Francisco, CA, USA, Aug. 2016, pp. 785–794.